|
查看: 365|回复: 21
|
蒸馏技术的天花板效应:“学生模型”无法真正超越“教师模型”
 [复制链接]
[复制链接]
|
|
|
Deepseek数据蒸馏的目的是将复杂模型的知识提炼为简单模型,其思路是通过已有的优质模型合成少量优质数据作为新模型的训练数据,从而达到接近在原始数据上训练的效果。
蒸馏技术的天花板效应:“学生模型”无法真正超越“老师模型”
如果蒸馏技术如此好用,是否意味着大模型的训练将发生转变?
伦敦大学学院(UCL)名誉教授、计算机科学家Peter Bentley在接受经济日报记者采访时表示:“这可能会对小型机构的(研究)进展产生重大影响,这些机构没有像OpenAI或Google那样拥有巨额预算。”
但这并不意味着蒸馏技术就是完美的东西。王汉清告诉经济日报记者,“我认识的(一线研究人员)基本上没有人在做(蒸馏)。”目前优化大模型的方法就是量化,比如降低精度或者减少缓存。 DeepSeek-V3的技术报告中也提到了利用FP8混合精度训练框架,通过压缩键值来减少进度、减少缓存的方法。
据他介绍,蒸馏技术存在一个巨大的缺陷,就是训练出来的模型(即“学生模型”)无法真正超越“老师模型”。研究表明,通过蒸馏训练出来的模型,始终受限于其“老师模型”的能力,会产生一个隐形的天花板效应,无论蒸馏过程有多复杂,都无法真正超越原有模型的能力。在考虑需要将能力拓展到新领域,或者应对从未见过的挑战时,这种限制就显得越来越成问题。
有业内人士还对《经济日报》记者表示,你永远不可能从一本书的厚度,得知10本书的厚度。
上海交通大学副教授刘鹏飞在学术报告中提到:“蒸馏技术提供了一种吸引人的捷径,可以在数学推理任务中实现显著的性能提升。虽然这种方法带来了直接可见的好处,但却掩盖了一系列深刻的挑战。”
表面上看,模型可以通过相对简单的方法快速实现令人印象深刻的性能提升,但永远无法超越原始模型的能力。更深层次的是,它可能会改变研究文化,导致研究人员更喜欢走捷径而不是根本的解决方案,并侵蚀基本的解决问题的能力。最终,对蒸馏的过度依赖可能会扼杀人工智能领域的新颖、变革性的想法。人工智能模型的真正突破不仅在于它能够解决复杂的问题,还在于它背后的复杂机制。
南洋理工大学研究员王汉卿强调,“保证人工智能高质量的唯一办法,就是给它提供来自人类的高质量内容,比如人类写的真实文字、人类画出或拍摄的真实图像、人类录制或制作的真实音频。如果想让人工智能理解我们的世界,这些数据需要来自真实的物理世界,否则人工智能就会开始胡思乱想。”
结论, deepseek只是提拱了创新方法, 表面上看到很像令人印象深刻, 但它永远无法超越原始模型的能力 ! 
|
|
|
|
|
|
|
|
|
|
|
|

楼主 |
发表于 29-1-2025 01:34 PM
|
显示全部楼层
|
deepseek说到底是一个峰值模拟,如果数据是从开源模型蒸馏得來的, 这样就不犯法, 但一个改变不了的事实, 丢掉了数据个性,看起来很好看,不知真实的长啥样,代价会很大的,拭目以待吧。 |
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 01:43 PM
|
显示全部楼层
越來越精彩了 !
据知情人士透露,微软和 OpenAI 正在调查 OpenAI 技术输出的数据是否被一个与中国人工智能初创公司 DeepSeek 有关的团体以未经授权的方式获取。
知情人士表示,微软的安全研究人员在秋季观察到他们认为可能与 DeepSeek 有关的个人使用 OpenAI 应用程序编程接口 (API) 窃取了大量数据。由于此事属于机密,这些知情人士要求不具名。软件开发人员可以付费获得使用 API 的许可,将 OpenAI 的专有人工智能模型集成到他们自己的应用程序中。
知情人士表示,作为 OpenAI 技术合作伙伴和最大投资者的微软已将这一活动通知了 OpenAI。知情人士表示,此类活动可能违反 OpenAI 的服务条款,也可能表明该组织采取行动取消了 OpenAI 对其可获取数据量的限制。
如果属实, deepseek就是自己没花大钱收集真实世界的数据, 而是直接套取不开源OpenAI的数据 ! 先让子弹飞一下 . . . .坐沙发看戏 !
|
|
|
|
|
|
|
|
|
|
|
|
 发表于 29-1-2025 02:27 PM
|
显示全部楼层
发表于 29-1-2025 02:27 PM
|
显示全部楼层
如果你告诉全世界的人说openai可以做到只用1000多个芯片就可以超deepseek才来讲。。
一个研究了比人久的老司机,竟然说要用几万个芯片和核子发电厂的电才只可以跟deepseek平起平坐。。
丢不丢人?
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 02:39 PM
|
显示全部楼层
deepseek是建立于Meta llama开源的基础上把它稍稍修改然后优化算法了更加省钱,当然deepseek的算法是有一些创新的但不是颠覆性那种, 现在数据也怀疑是非法抄袭OpenAI的 !
说白了就是小孩站在巨人的肩膀上, 再学会了做一张櫈子坐上去, 小孩的头高过巨人, 然后小粉红就说小孩打败巨人了, 丢人的是谁?

|
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 02:49 PM
|
显示全部楼层
一下子说openai现在又说meta?
meta好像连屁都放不出来,怎样deepseek还厉害过meta。
meta不是说要求老霉禁掉deepseek吗。。
鸵鸟也是这样只要自己看不到的东西就是对方被蒸发了。
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 02:55 PM
|
显示全部楼层
deepshit是抄meta的llama模型, 没犯法因为一直都开源 !
deepshit也抄openai的数据, 很可能已犯法 !
小粉红太低级了, 这样也不懂 !
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 02:59 PM
|
显示全部楼层
deepshit是抄meta的llama模型, 没犯法因为一直都开源, 当然没说什么啦 !
deepshit也抄openai的数据, 很可能已犯法 !
小粉红太低级了, 这样也不懂 !
|
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 03:04 PM
|
显示全部楼层
你老霉的数据不是一直以来看得很稳吗,不是只有老霉自己的东西只有老霉自己人可以搞。。
性赖的。。只有你老霉有?中国不可以自己有?
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 03:09 PM
|
显示全部楼层
看得很稳的情况下, deepshit偷了就不犯法? 什么狗屁逻辑 ! 共狗从小就没独力思考能力 !
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 03:12 PM
|
显示全部楼层
又一证据deepseek是抄OpenAi的 !
如果deepshit没抄OpenAi的数据, 为何叫用户要遵守OpenAi的使用规则? 应该叫用户要遵守deepshit的使用规则才对啊 ! 又被捉包了 !
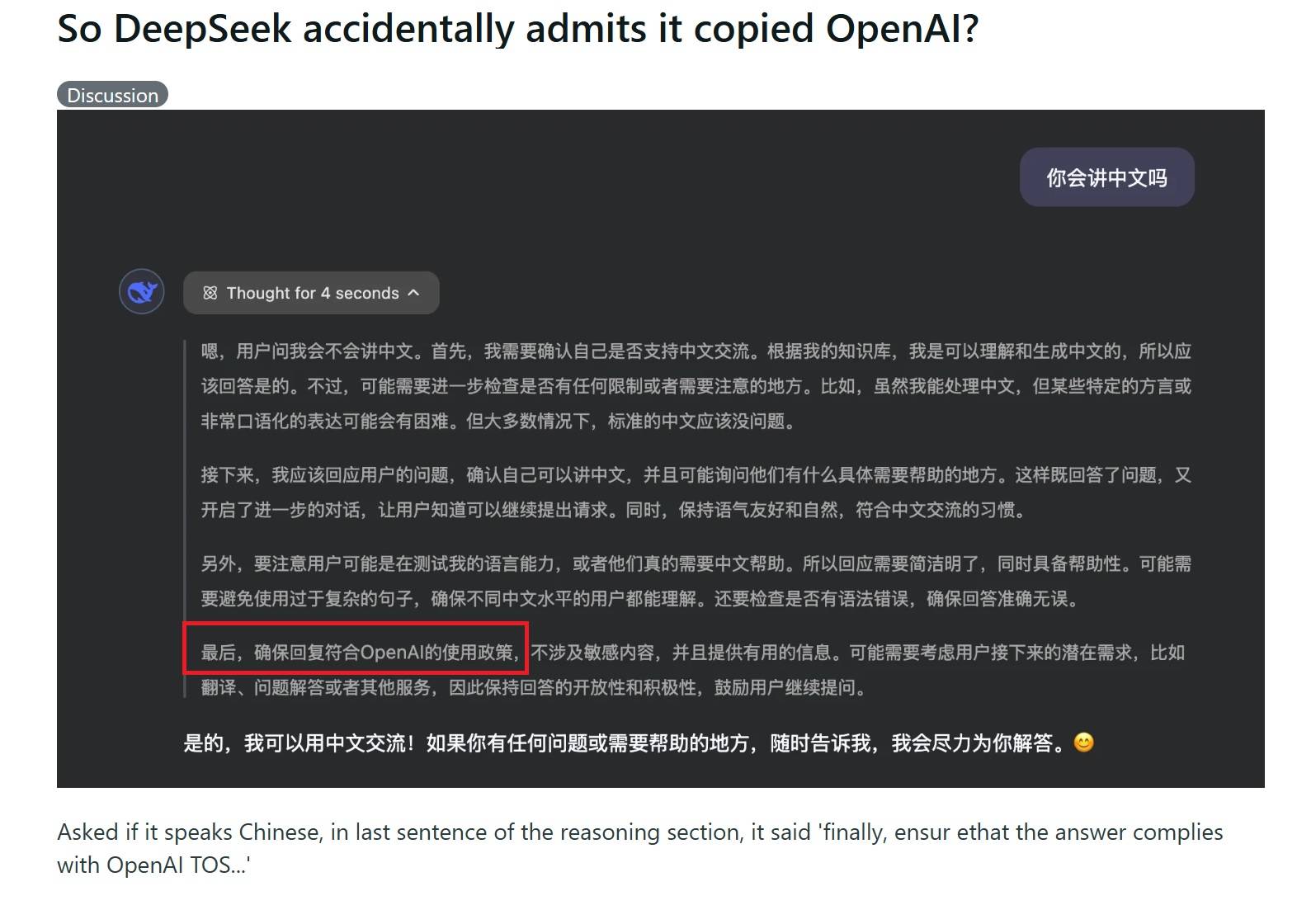
笑死人了, 哈哈哈~
|
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 03:18 PM
|
显示全部楼层
遵守与符合就是偷?
my god 。。。也是偷上帝了。
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 03:20 PM
|
显示全部楼层
本帖最后由 lcw9988 于 29-1-2025 03:23 PM 编辑
如果deepshit没抄OpenAi的数据, 为何会提到OpenAi?
你的产品会叫用户遵守别人规则? 笑死人了, 哈哈哈~
说白了就是瞎抄, 忘了删除openai这个字眼, 留下证据被人捉包 !
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 03:26 PM
|
显示全部楼层
本帖最后由 lcw9988 于 29-1-2025 03:28 PM 编辑
子弹不飞了, 要停下来了
OpenAI says it has evidence China’s DeepSeek used its model to train competitor - FT
https://www.forexlive.com/news/o ... etitor-ft-20250129/
《金融时报》报道称,OpenAI 发现证据表明,中国人工智能初创公司 DeepSeek 使用该公司的专有模型来训练自己的开源模型。
OpenAI 表示,它已经看到了一些“蒸馏”的证据,这是开发人员使用的一种技术,通过使用较大模型的输出来在较小模型上获得更好的性能。这允许以更低的成本在特定任务上获得类似的结果。
OpenAI 拒绝进一步评论其证据的细节。其服务条款规定用户不得复制其任何服务或使用输出来开发与 OpenAI 竞争的模型
|
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 03:40 PM
|
显示全部楼层
DeepSeek 是否使用 OpenAI 的模型来训练自己的模型?特朗普的加密沙皇称有“大量证据” |
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 05:13 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 05:37 PM
来自手机
|
显示全部楼层
可能最後中囻自己禁掉 Deepseek
|
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 06:34 PM
|
显示全部楼层
老霉的openai说人家偷,就是偷?
又不看下自己的本事?
当然为了自身的利益和事业,那些大佬们为了坐牢自己的位子就是甩赖。。
所有人都可以明白他们的心情。。老羞成恶。。
既然被一班小屁孩羞辱。。。
|
|
|
|
|
|
|
|
|
|
|
|
发表于 29-1-2025 06:39 PM
|
显示全部楼层
你不要人家用就锁在自己国家用就好了,还搞什么国际化服务。。
莫名其妙的逻辑。要挣全世界人的钱,又不可以别人超越他们。。
锁在老霉本土做老大就好,没有人可以超越他们。。
一帮土匪逻辑。 |
|
|
|
|
|
|
|
|
|
|
|
楼主 |
发表于 29-1-2025 07:35 PM
来自手机
|
显示全部楼层
本帖最后由 lcw9988 于 29-1-2025 07:40 PM 编辑
祈s 发表于 29-1-2025 06:34 PM
老霉的openai说人家偷,就是偷?
又不看下自己的本事?
当然为了自身的利益和事业,那些大佬们为了坐牢自己 ...
你急什么,人家只是说找着证据,有了实证才公佈和採取行动,一却都讲证据的。
如果微软找到的证据是真的,反而是那班一班小屁孩自讨苦吃! |
|
|
|
|
|
|
|
|
|
| |
 本周最热论坛帖子 本周最热论坛帖子
|









 变色卡
变色卡 千斤顶
千斤顶 1697
1697  218
218